What Is a B2B Data Layer? And Why Revenue Teams Need One in 2026
80% of AI projects fail — not because of the model, but the data underneath it. Most revenue teams have a CRM, a sequencer, and a data tool. What they don't have is a data layer. This guide covers what it is, why it's different, and why it matters more in 2026 than ever.


A B2B data layer is the infrastructure that continuously supplies verified, structured, and locally-sourced business intelligence to every tool in a revenue team's stack — the CRM, the sequencer, the AI agents, the enrichment workflow, and the reporting layer. It is not a data tool you log into to search for contacts. It is the underlying source of truth that feeds everything else. The distinction matters because most revenue teams have data tools — Apollo, ZoomInfo, Lusha, Cognism — but not a data layer. A data tool is a product you use. A data layer is infrastructure you build on. As AI agents take over more of the outbound workflow in 2026, the data layer underneath them determines how far those agents can actually reach — and whether they produce results or hallucinate on empty fields.
Here is a fact that should reshape how you think about your GTM stack: more than 80% of AI projects fail — twice the rate of traditional technology programmes. The most common cause is not a bad model or a bad prompt. It is bad data infrastructure underneath the model.
The same pattern plays out in B2B revenue teams. Companies invest in AI-powered sequencers, agentic outbound tools, and revenue intelligence platforms — then wonder why the outputs are generic, the personalization is hollow, and the pipeline is thin. The tool is not the problem. The data layer underneath it is.
What a data layer actually is
A B2B data layer is infrastructure — not a product you log into, but a foundation you build on top of. Three defining characteristics:
It is continuous, not point-in-time. B2B contact data decays at roughly 30% per year (ZoomInfo and HubSpot research). A data tool returns a result when you search — and that result decays until you search again. A data layer monitors local registries, job platforms, and trade press continuously, compensating for decay in real time.
It feeds other systems, not just human users. A data tool is designed for a person to query. A data layer is designed to supply verified, structured data to every downstream system that needs it — the CRM, the AI agent, the enrichment workflow, the sequencer, the reporting layer. In 2026, the biggest data consumer in most companies is not the BI analyst — it is the AI agents. Those agents need continuous access to structured, trustworthy data — not a query-on-demand tool that waits for a human.
It covers the full addressable market, not just the indexed one. Most data tools were built from English-language infrastructure — LinkedIn, Crunchbase, national press, US business registries. They cover the portion of the global B2B market that happens to appear in English-language sources. A data layer sources from official registries, regional platforms, and local-language sources in each market — covering the full company universe, not just the fraction visible to English-language tools.
Why the data layer matters more in 2026 than it ever has
Three things changed in 2026 that make data infrastructure the highest-leverage investment in a modern GTM stack.
AI agents are now the primary data consumers. More than 40% of agentic AI initiatives are projected to be cancelled by 2027 — not because the models fail, but because the data infrastructure underneath them is incomplete, stale, or geographically limited. An agent fed empty fields does not produce a generic output. It hallucinates one. A live data layer is what prevents this.
The CRM is not a data layer — it is a system of record. CRM systems like Salesforce and HubSpot store what your team knows about an account. They do not continuously verify whether what is stored is still accurate, or surface new signals about accounts that have not been touched recently. CRM data alone is incomplete — missing contacts, outdated titles, and company changes create blind spots. Without a live data layer, the system of record is also a system of decay — losing accuracy on nearly one in three records every year.
The global coverage gap is costing pipeline. The majority of the world's B2B companies generate their digital footprint through local registries and regional platforms in their own markets — not through LinkedIn or Crunchbase. A revenue team targeting Indonesia, Saudi Arabia, or non-Anglophone Europe with a data tool built from English-language infrastructure is operating from a partial map. The accounts exist and the signals are firing — the infrastructure just was not built to see them.
| Dimension | Data tool (Apollo, Lusha, ZoomInfo) | Data layer (Pubrio) |
|---|---|---|
| Primary user | Human SDR or marketer querying for a contact or list | CRM, AI agents, enrichment workflows, sequencers — all downstream systems simultaneously |
| Data freshness | Point-in-time — verified when collected, decays until next query | Continuous — local registries, job platforms, and trade press monitored in real time |
| Source architecture | English-language infrastructure — LinkedIn, Crunchbase, national press, US registries | Local-source infrastructure in each market — 50+ registries, regional platforms, local-language trade press across 130+ countries |
| Signal intelligence | Static firmographics + English-language intent co-op signals | 120,000+ daily Expansion Signals from local ecosystems — registry filings, regional hiring, local-language funding events |
| AI agent compatibility | Query-on-demand — agent must initiate each lookup; no live feed | API and MCP-native — agents, workflows, and integrations call the layer continuously |
| Geographic coverage | Strong for North America and Western Europe; thin for APAC, MENA, and non-Anglophone markets | Local-source coverage across 130+ countries — including markets where data tools return empty |
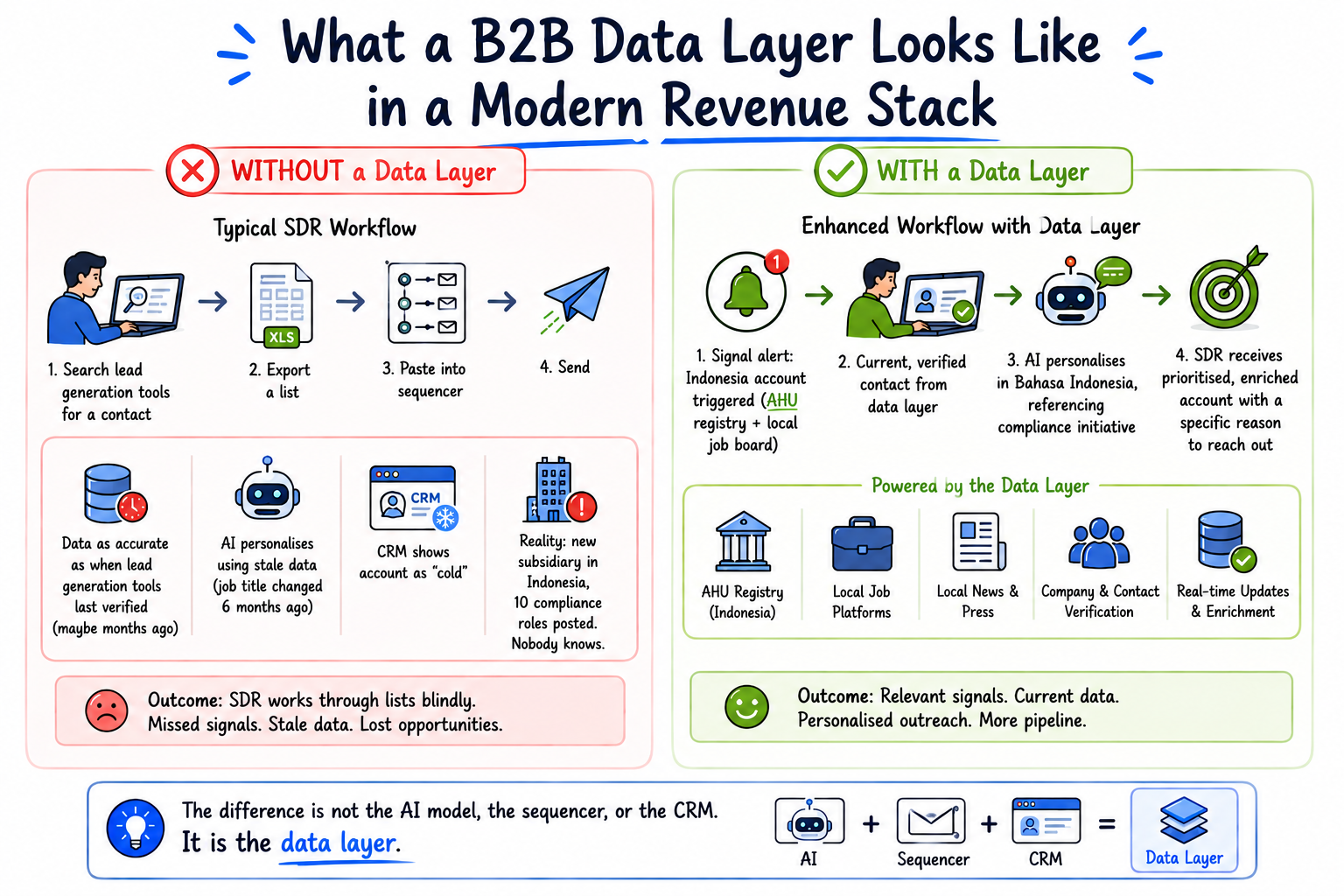
What a B2B data layer looks like in a modern revenue stack
In a stack without a data layer, the workflow looks like this: an SDR searches lead generation tools for a contact, exports a list, pastes it into a sequencer, and sends. The data is as accurate as it was when the lead generation tools last verified those records — which may be months ago. The AI agent used for personalisation queries the same stale record and produces personalised copy based on a job title that changed six months ago. The CRM shows an account as "cold" because no one has touched it — but the account just registered a new subsidiary in Indonesia and posted ten compliance roles on a local job board. Nobody knows.
With a data layer underneath the stack, the workflow is different. The account in Indonesia shows up in a signal alert because the data layer is monitoring the AHU registry in real time. The contact record is current because the data layer has re-verified it against the local job platform where that person recently posted an update. The AI agent personalises outreach in Bahasa Indonesia, referencing the compliance initiative the hiring signal reveals, because the data layer has supplied local context that no English-language tool could produce. The SDR receives a prioritised, enriched account with a specific reason to reach out — not a list of 500 contacts to work through.
The difference is not the AI model, the sequencer, or the CRM. It is the data layer.
Pubrio as a B2B data layer
Pubrio was built as a data layer, not a data tool. It does not just return contacts when queried. It sources continuously from 50+ local registries and regional data sources in each of the 130+ countries it covers. It generates 120,000+ daily Expansion Signals from local ecosystems. It exposes structured data via API and MCP-native integrations so that AI agents, enrichment workflows, and downstream systems can consume it continuously — not just when a human remembers to log in and search.
1B+ profiles from 50+ local sources across 130+ countries. From $125/month. Free plan available.
on a Real Data Layer